If you are looking to bring your product idea to life with Canadian design and electronic contract manufacturing expertise, connect with us.
Designing Integrated Hardware and Software Systems That Scale
Connected products are no longer defined solely by hardware. Today’s devices are layered systems in which hardware, firmware, and cloud infrastructure must operate as a cohesive whole. When these layers are developed independently and stitched together late in the process, integration problems surface at the worst possible time, often when products are already in the field.
In our experience building embedded systems across industries, one principle consistently proves true: integration cannot be an afterthought. Alignment must begin on day one of the design process.
Integration as a Process
When we talk about integrated hardware–software systems, we are referring to two things. First, the way teams collaborate during development. Second, how the system itself is architected across layers.
From a process standpoint, integration begins with co-design. Hardware, firmware, and cloud teams must align early around shared requirements and a clearly defined end goal. Ambiguities resolved early are exponentially cheaper than issues discovered late in integration or, even worse, during deployment. When teams collaborate from the outset, trade-offs become visible, and decisions are made intentionally rather than reactively.
From an architectural standpoint, integration means designing hardware, firmware, and cloud as a unified system rather than independent components. Each layer should be robust on its own, yet aware that it operates as part of something larger. For example, hardware must fail safely, firmware should continue functioning even when cloud connectivity is interrupted and a cloud outage should never disable an entire fleet.
Developing in silos results in costly assumptions and ultimately a poor design. Offloading tasks to firmware without verifying its feasibility can be extremely damaging in the design process as our team and I have learned the hard way. In one case, audio mixing was offloaded to firmware without fully accounting for its computational load. The hardware lacked a dedicated audio codec, and once integration began, resource constraints became apparent. Thankfully, a later hardware respin increased available memory and compute, allowing the feature to function, though with reduced audio quality and fewer audio streams than originally intended. The lesson was clear: partitioning responsibilities across layers must be deliberate and validated collaboratively. And ultimately, important design decisions are best made as a team.
Designing for Scale From the Beginning
It is tempting to design around a prototype mindset. But the difference in the reliability of a deployment of ten units vs. ten thousand units is not incremental, it is exponential.
Low-probability issues that seem harmless during testing inevitably surface at scale. A failure rate of 0.1% may appear negligible until thousands of devices are deployed. At that point, rare issues become guaranteed realities.
Designing for scale requires margin. Hardware should not be designed for theoretical requirements. Extra RAM, additional flash, compute headroom, and appropriate hardware derating will create breathing room for future features, unforeseen constraints and unaccounted tolerances. Firmware should support over-the-air updates from the start, ideally with rollback capabilities, and secure boot authentication. Cloud infrastructure should be built with observability in mind, including centralized logging, versioned endpoints, and metrics that reveal system behaviour in real-world conditions.
Scalability is not simply about handling growth. It is about ensuring that growth does not amplify weaknesses.
Hardware: The Most Expensive Commitment
Among the three layers, hardware carries the highest cost of error. Firmware bugs can often be corrected remotely. Hardware mistakes typically require respins, redesigns, or, in extreme cases, recalls.
This makes system-level validation critical. Testing individual components against their specifications is not enough. Integration exposes constraints that isolated testing rarely reveals. Component tolerances create variability and stress at startup. Sensors are noisy and inconsistent. Timing interactions between subsystems can create deadlocks and edge cases that do not appear on a bench.
In one of our projects, sufficient nominal power was designed into the system. However, during startup, the inrush current caused intermittent failures. The issue did not appear until production volumes scaled into the thousands and marginal failure rates got multiplied across the deployment. Because startup events and failures were not thoroughly logged, diagnosis was delayed. A workaround was eventually implemented by staggering peripheral initialization and leveraging redundant hardware controls built into the design. While this prevented a recall, it reinforced a key lesson: validating hardware behaviour at the system level is essential.
Good hardware architecture does not always eliminate failure, but it can provide flexibility and recoverability when failures occur.
Firmware: Engineering for Resilience
Firmware acts as a bridge between hardware and the cloud, serving as the system’s resilience layer. It must account for unreliable networks, constrained resources, and real-world unpredictability.
Designing firmware for success alone is insufficient. Systems must be able to fail gracefully. Watchdog timers, supervisory tasks, health checks, and recovery modes prevent devices from entering unrecoverable states. Over-the-air update pipelines should include rollback support and dual-image strategies to protect against corrupted or insecure firmware. As fleets evolve, backward compatibility becomes essential; devices rarely update simultaneously, and version mismatches must be anticipated by ensuring simultaneous compatibility across versions.
The Role of Edge Computing
As embedded systems become more powerful, more intelligence can be pushed to the edge. Computing at or near the point of data collection reduces dependence on cloud connectivity and enables real-time decision-making. It also distributes computational load across devices, preventing the cloud from becoming a bottleneck as fleets expand, and the system becomes more powerful and more resilient.
Emerging innovations, including specialized analog and mixed-signal AI chips, are further extending what can be done at the edge. Tasks such as anomaly detection, image recognition, and gesture detection are already being performed on embedded devices. However, implementing AI at the edge requires careful component selection and thoughtful resource budgeting. Signal quality from sensors remains paramount; no model or algorithm can compensate for fundamentally poor data.
The shift toward edge intelligence does not replace the cloud. It rebalances responsibility across the system.
For a deeper look at the practical limitations of deploying AI at the edge, explore our articles on Hardware constraints in Edge AI and Firmware constraints in Edge AI.
Cloud: Most flexible, yet most exposed
The cloud layer is typically the most adaptable component of a connected system. It supports fleet-wide OTA updates, centralized monitoring, analytics, and user-facing features. Yet it is also the most exposed, as it is internet-facing by default and often serves as the primary access point to the fleet.
Security, therefore, cannot be layered on after deployment. Authentication, authorization, secure update delivery, and endpoint versioning must be built into the architecture from the beginning. Observability across the fleet is equally important. Without logging and traceability, diagnosing issues becomes guesswork rather than engineering.
The cloud should unify the fleet into a system without introducing fragility.
Integration as a Foundation, Not a Phase
No team can anticipate every failure mode. Complex systems inevitably produce edge cases. What distinguishes resilient products from fragile ones is not the absence of problems, but the ability to adapt when problems arise and fail gracefully.
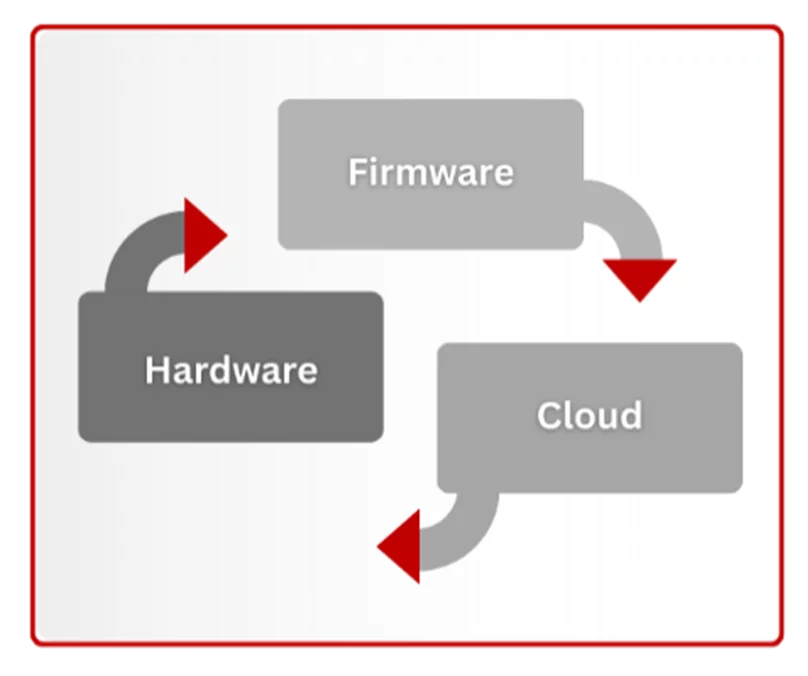
In practice, the most successful projects share common traits: early cross-functional collaboration, intentional partitioning of responsibilities in between system layers, built-in design margins, and comprehensive logging across layers. When hardware, firmware, and the cloud are developed as a unified system, teams gain control over integration rather than having to react to it.
Integration is not a final milestone before launch. It is the foundation upon which scalable, secure, and reliable products are built.
And at scale, that foundation makes all the difference.
If you are facing Integration challenges between your hardware, software and cloud teams, let's talk. The lessons our team has gathered along the years can help reduce your time-to-market and bring your product to life more efficiently.
All Blogs